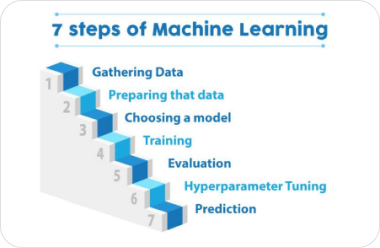
Machine learning can be a difficult concept to grasp, so let’s take a step-by-step approachtowards understanding machine learning.
Machine learning can be a complex topic, but at its core, it’s all about teaching a computer program to learn from data. Here’s how it works:
- Data Collection: The first step in machine learning is collecting data. This can come from a variety of sources, such as sensors, databases, or user interactions. The data should be relevant to the task at hand and representative of the problem you want to solve.
- Data Preprocessing: Once you have your data, you need to clean and preprocess it. This involves removing irrelevant data, filling in missing values, and transforming the data into a format that can be used by the machine learning algorithm.
- Training: The next step is to train a machine learning model on the preprocessed data. The model will learn the underlying patterns and relationships between the inputs and outputs by adjusting its internal parameters.
- Validation: After training, the model needs to be validated to ensure that it’s accurate and reliable. This involves testing the model on a separate dataset that it hasn’t seen before and comparing its predictions to the actual outputs.
- Testing: Once the model has been validated, it’s ready to be used in the real world. This involves testing it on new, unseen data and monitoring its performance over time.
- Improvement: Machine learning is an iterative process, and there’s always room for improvement. As you collect more data and gain more insights, you can fine-tune your model to make it more accurate and effective.
In summary, machine learning involves collecting and preprocessing data, training a model on the data, validating the model, testing it on new data, and improving it over time. By following this step-by-step approach, you can teach a machine to learn from data and make accurate predictions or decisions.